1. Word Length Analysis
Code Example:
def word_length(filename):
file = open(filename)
line = file.readline()
count = 0
while line != '':
word_list = line.split()
for word in word_list:
count += len(word)
line = file.readline()
return count
Explanation:
This function calculates the total length of all words in a speech. We get every single line in the text, split every single word in the line into the list, and using len() function to get the length of words in lines in text
2. Word Count
Code Example:
def word_count(filename):
file = open(filename)
line = file.readline()
count = 0
while line != '':
word_list = line.split()
for word in word_list:
count += 1
line = file.readline()
return count
Explanation:
This function calculates the total number of words in a speech. We read every line in the text, split it into a list of words, and count the words in the list by iterating through them. The sum of all the words in all lines gives us the word count.
3. Sentence Count
Code Example:
def sentence_count(filename):
file = open(filename)
line = file.readline()
count = 0
while line != '':
for word in line:
if word == ".":
count += 1
line = file.readline()
return count
Explanation:
This function calculates the total number of sentences in a speech. We go through every line in the text and check each character in the line for a period (.). Each occurrence of a period increases the sentence count by one.
4. Average Sentence Length
Code Example:
def average_word_in_sen(filename):
word_number = word_count(filename)
sentence_number = sentence_count(filename)
average_word_in_sen = word_number / sentence_number
return average_word_in_sen
Explanation:
This function calculates the average number of words per sentence. We first get the total word count and the total sentence count, then divide the word count by the sentence count to find the average.
5. Line Count
Code Example:
def line_count(filename):
file = open(filename)
line = file.readline()
count = 1
while line != '':
line = file.readline()
count += 1
return count
Explanation:
This function calculates the total number of lines in the speech. We go through each line in the text, and for every line read, we increase the count by one.
6. Average Line Length
Code Example:
def average_line_length(filename):
line_number = line_count(filename)
word_number = word_count(filename)
return word_number / line_number
Explanation:
This function calculates the average number of words per line. We divide the total word count by the total line count to compute this value.
7. Punctuation Marks
Code Example:
import string def punctuation_marks(filename):
file = open(filename)
line = file.readline()
punc = string.punctuation
count = 0
while line != '':
for i in line:
if i in punc:
count += 1
line = file.readline()
return count
Explanation:
This function calculates the total number of punctuation marks in a speech. We read every line and check each character to see if it matches any symbol in string.punctuation. Each match increases the punctuation count by one.
8. Average Sentence Complexity
Code Example:
def average_sentence_complexity(filename):
sentence_number = sentence_count(filename)
amount_punc = punctuation_marks(filename)
return amount_punc / sentence_number
Explanation:
This function calculates the average sentence complexity by finding the average number of punctuation marks per sentence. We divide the total punctuation count by the total sentence count to compute this.
9. Average Word Length
Code Example:
def average_word_length(filename):
return word_length(filename) / word_count(filename)
Explanation:
This function calculates the average length of words in a speech. We divide the total length of all words by the total number of words to compute this value.
1. aspects_listing() Function
Code Example:
def aspects_listing(filename):
temp = []
temp.append(round(word_length(filename),2))
temp.append(round(word_count(filename),2))
temp.append(round(sentence_count(filename),2))
temp.append(round(average_word_in_sen(filename),2))
temp.append(round(line_count(filename),2))
temp.append(round(average_line_length(filename),2))
temp.append(round(punctuation_marks(filename),2))
temp.append(round(average_sentence_complexity(filename),2))
temp.append(round(average_word_length(filename),2))
return temp
Explanation:
This function collects multiple aspects of the text into a list. It uses previously defined functions to calculate various metrics (e.g., word length, word count, sentence complexity) for the given file. Each value is rounded to two decimal places and added to the list in a specific order. The resulting list serves as a compact representation of a text’s stylistic attributes, and we use that as data for drawing graphs.
2. Scatter Plot: plot_scatter_graph()
Code:
import matplotlib.pyplot as plt def plot_scatter_graph():
files = [
"MIT Mid-Century Convocation",
"Sinews of Peace, 1946",
"The Council of Europe, 1949",
"Victory in Europe, 1945",
"Winston Churchill announces the Sur"
]
x_data = []
x_data.append(aspects_listing('MIT Mid-Century
Convocation.txt')[8])
x_data.append(aspects_listing('Sinews of Peace, 1946.txt')[8])
x_data.append(aspects_listing('The Council of Europe, 1949
(1).txt')[8])
x_data.append(aspects_listing('Victory in Europe, 1945.txt')[8])
x_data.append(aspects_listing('Winston Churchill announces the
Sur.txt')[8])
y_data = []
y_data.append(aspects_listing('MIT Mid-Century
Convocation.txt')[7])
y_data.append(aspects_listing('Sinews of Peace, 1946.txt')[7])
y_data.append(aspects_listing('The Council of Europe, 1949
(1).txt')[7])
y_data.append(aspects_listing('Victory in Europe, 1945.txt')[7])
y_data.append(aspects_listing('Winston Churchill announces the
Sur.txt')[7])
plt.scatter(x_data, y_data)
for i in range(5):
plt.text(x_data[i],y_data[i],files[i])
plt.title("Word Length vs Sentence Complexity in some texts")
plt.ylabel("Word Length")
plt.xlabel("Sentence Complexity")
plt.show()
plot_scatter_graph()
Explanation:
This function generates a scatter plot comparing average word length (x-axis) to sentence complexity (y-axis) across five speeches.
● Data Preparation:
It uses the aspects_listing function to extract the required metrics (average word length and sentence complexity) for each speech.
● Visualization:
Each data point represents a speech, and text labels indicate the speech titles. The relationship between these two metrics is visualized, helping to identify stylistic differences. For instance, speeches with higher sentence complexity may reflect a formal style.
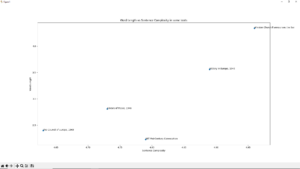
3. 3D Scatter Plot: three_dimension_graph() Code:
python Copy code
def three_dimension_graph():
ax = plt.axes(projection="3d")
files = [
"MIT Mid-Century Convocation",
"Sinews of Peace, 1946",
"The Council of Europe, 1949",
"Victory in Europe, 1945",
"Winston Churchill announces the Sur"
]
x_data = [aspects_listing(filename)[8] for filename in
file_list]
y_data = [aspects_listing(filename)[7] for filename in file_list]
z_data = [aspects_listing(filename)[5] for filename in file_list]
ax.scatter(x_data, y_data, z_data)
for i in range(len(files)):
ax.text(x_data[i], y_data[i], z_data[i], files[i])
ax.set_title("Word Length vs Sentence Complexity vs Line Length
in some texts")
ax.set_xlabel("Sentence Complexity")
ax.set_ylabel("Word Length")
ax.set_zlabel("Line Length")
plt.show()
Explanation:
This function creates a 3D scatter plot to compare three stylistic metrics:
- x-axis (Sentence Complexity): Average punctuation marks per sentence.
- y-axis (Word Length): Average word length.
- z-axis (Line Length): Average line length.

● Data Preparation:
The aspects_listing function extracts the required metrics for each speech. ● Visualization:
Each point in the 3D space represents a speech. The axes provide a three-dimensional view of how sentence complexity, word length, and line length interact. Speeches with higher values in these metrics may suggest a more formal or complex structure.