Every year the Digital Classics Association (DCA) sponsors a panel at the meetings of the Society for Classical Studies (SCS), and this year, appropriately, it was all about the potential of LLMs and AI in classical philology. Organized by Neil Coffee, the driving force behind DCA, it was a star-studded panel. Here is (was) the program:
Opening Up Classics with AI (organized by the Digital Classics Association)
Neil Coffee, University at Buffalo, SUNY, Organizer
- Neil Coffee, University at Buffalo, SUNY
Introduction - Samuel Huskey, University of Oklahoma
Opening Up Bottlenecks in Digital Classics Workflows with Human-in-the-Loop AI - Patrick Burns, New York University
Prompt Engineering for Latin Teachers - Edward Ross, University of Reading, and Jackie Baines, University of Reading
Generative Image AI and Teaching Classics: A Case of Exaggeration - Gregory Crane, Tufts University
AI, Machine Actionable Publication and Assigning Credit - Joseph Dexter, Harvard University, and Pramit Chaudhuri, University of Texas at Austin
Benchmarking Generative AI Models for Classical Literary Criticism
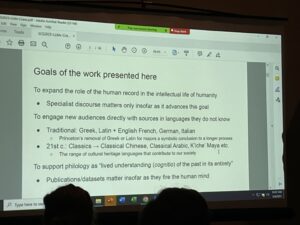
Gregory Crane, Tufts University
AI, Machine Actionable Publication and Assigning Credit
The abstracts of the talks are posted here, so I won’t try summarize them. My favorite quote came from the ever-polemical Gregory Crane, who referred to the monographs being sold nearby in the SCS book publishers’ display as “a dark archive,” and said “publications/datasets matter insofar as they fire the human mind.” That is a scholarly goal I can get behind, firing the human mind.
Huskey is working on the gathering comprehensive metadata for the Digital Latin Library, sucking in library records from all over the world and trying to disambiguate author names and work titles, many of which have multiple variants, confusing overlaps, and vagueness in the existing records (opera omnia? opera selecta? Bucolica? Eclogae?)
Burns is working on trying to create extensive reading material for Latin learners, as we go from the extreme scarcity of comprehensible texts for beginners to a world where we can have essentially infinite amounts of Latin pitched at any level. Charmingly, he had an LLM create a story about Odysseus and the Cyclops from the perspective of the sheep. From this talk I learned that prompts can be very large. A human will be confused by a question that is 300 pages long; AIs can easily take it in and synthesize. His main message is you can get a basic understanding of how this things work without being a computer scientist, and it is helpful to have such an understanding.
Ross and Baines are keeping track of AI-generated images that have something to do with the ancient world, and ferreting out distorted history, incorrect information, and modern biases. They showed an amusing image of “Nike the Greek Goddess” flying around wearing a pair of Nike sneakers. Images of Hades draw extensively from Disney’s Hercules. They believe scholars have a duty to keep track of the craziness that is out there, if only to help the image tools get gradually more historically accurate.
Dexter and Chaudhri just finished teaching a seminar on Latin literary history using only fragmentary authors, and are trying to use AI to craft a new narrative about Latin literary history based on this material.
Crane wants to leverage AI to give people without extensive knowledge of historical languages better access to the classics of the world, the whole world, through enhanced translations and reference tools, and to serve audiences in their own languages (e.g. Persian), not just English. I was particularly taken with his effort to us machine translation to translate the examples in Kuhner-Gerth’s Ausführliche Grammatik der griechischen Sprache into English, thus unlocking this fundamental reference work for a broader audience. He’s training AI to figure out which of the 26 uses of ὡς is active in a particular passage of Greek. He also pointed out the the multilingual OCR at Hathi Trust is off-the-chain good at this point.
What struck me was the way that using AI tools requires scholars to be explicit about their goals, what they really want to do, in a way that writing a journal article does not. These papers used AI tools for different, all legitimate, philological and scholarly goals. Do you want to
- critique historical bias and inaccuracy on the web? (Ross & Baines)
- tell a story about literary history? (Dexter and Chaudhuri)
- help people learn Latin? (Burns)
- catalogue published texts? (Huskey)
- attribute passages correctly? (Dexter and Chaudhuri)
- fire the human mind? (Crane)
AI can help. Notably, none of these goals is rewarded by the academic world as currently constituted. Which is one more reason I respect these scholars for doing interesting work despite the professional incentives to churn out another article or book for the dark archive.
I went into this panel rather repelled by AI, more aware of it as a tool for cheating on college writing assignments, and a potential menace to humanity, than as a potential aid in my beloved philology. I came out intrigued with the possibilities and wanting to try to apply it to the workflows of DCC (see this post on my first attempts to create DCC style vocabulary lists with ChatGPT and Claude).
Yuval Noah Harari’s fascinating 2024 book Nexus convinced me that there is no pre-determined end to the AI story, and that we need to be actively engaged in thinking about it and guiding its trajectory for human goals. Harari, a historian, talks about the ways that every new information technology brought good things and bad things. Printing enabled both the scientific revolution and witch hunts. What matters is how we use it and shape it. These papers all showed scholarly uses of AI that seem to me both interesting and productive.
Chris-this is great! I loved the quote about the ‘dark archive.’ I knew about the Hathi Trust (I think) but I’d not realised how extensive it is. Translating Kuhner-Gerth would be fun-I’ve spent toiling over bits of that (I’m sure I’m not the only one). I didn’t know the Nexus book. Also, going back to your other post-I’d not realised that long prompts would work so well.
The possibilities are just immense aren’t they? I found out about ChatGPT from something that Yasmin Haskell wrote on Facebook! Since Version 3.5 it’s just got better and better in my opinion. Then a couple of weeks ago I had a damascene moment and found Claude! I think he/she/it is very good at commenting on particular passages. It was also very perceptive when I experimented with the opening of Book 4 of the Argonautica! Incidentally Claude can make a reasonable attempt at writing Latin elegaics, if you give it a bit of help. It translated a W.B. Yeats poem for me the other day. It also (Chat GPT) taught me bits of Turkish at the end of last year! Anyway, that’s more than enough. I hope we can keep comparing notes about this. Happy New Year! Peter