Thalia, Muse of Comedy, from the Goddesses of the Greeks and Romans series (N188) issued by Wm. S. Kimball & Co.,1889. Metropolitan Museum.
The plays of Terence (P. Terentius Afer) are widely admired for their pure Latin style, but there is as yet no parsed text in digital form that would permit valid statistical analysis of his language and the creation of accurate vocabulary lists to ease reading via tools like The Bridge. If and when DCC publishes an edition of a play of Terence, having a text in which each word form is associated with its correct dictionary headword (lemma) will make the creation of the vocabulary lists a relative snap. Computers can’t accurately parse texts on their own, but humans used to do it routinely in the genre of book known as the concordance or index verborum. With the help of Dickinson computer scientist Michael Skalak, Bret Mulligan of Haverford and I have been working on project to convert older concordances and indices verborum into parsed texts by essentially unscrambling them so they are organized by text location rather then alphabetically by headword, and putting the data into an openly published and freely available spreadsheet. We have successfully completed the transformation of print concordances to Lucretius, Apuleius, and Eutropius, and now we are on to Terence, based on a professionally digitized version of Index Verborum Terentianus by Edgar B. Jenkins (Chapel Hill: The University of North Carolina Press, 1932, Pp. ix +187). (Worldcat record).
Jenkins’ book was meticulous, and it was well-received. Writing in Classical Review 47.1 (1933) 22-23 J.D. Craig called it “a miracle of compression without obscurity,” and he spotted only a small number of errors. Jenkins based his index on the text of Knauer and Lindsay, which is still in use (and on PHI). In each case, transformation from an alphabetical word list into a sequential parsed text requires careful examination of the system of listing lemmas, word forms, citations, and textual variants. Classical concordances are all slightly different in the conventions they employ.
The main peculiarity of Jenkins’ books is that he used a system of hyphenation, presumably to save space. This will have to be overcome by alteration of the base code for Michael Skalak’s Concordance Processor (code on Github). For my part, I had to filter out some information that was evidently important to Jenkins, but is not to us. For example, Jenkins put in parentheses all citations for words that are in parentheses in the text itself. Whether or not a word is in parentheses is immaterial to us, and having those citations in parentheses would have meant those citations were misinterpreted by the processor.
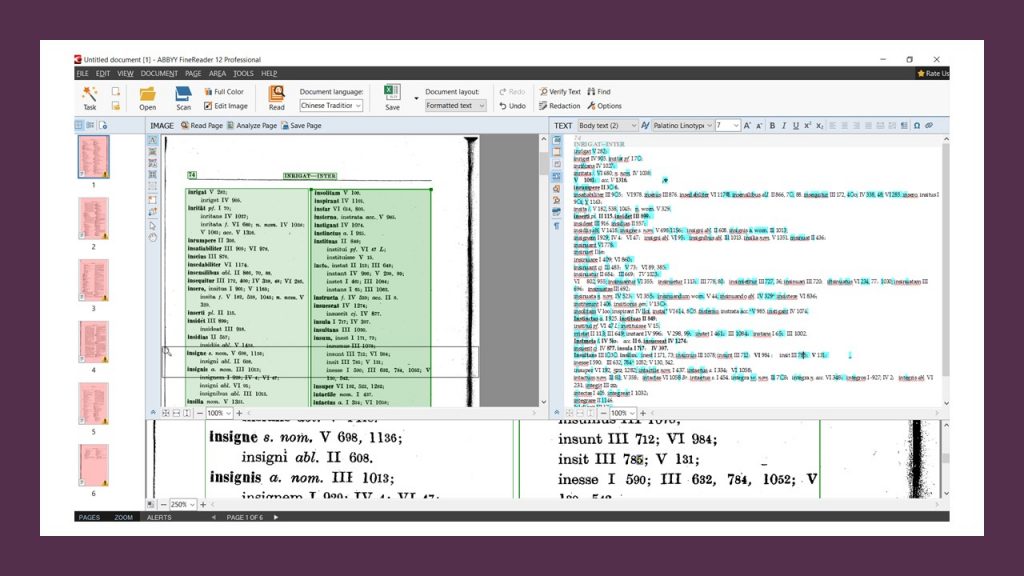
For the benefit of anybody who wants to try to do this kind of work in the future (and there are innumerable concordances that could be liberated in this way), here are my working notes and analysis of Jenkins. A random chunk of the .pdf looks like this:
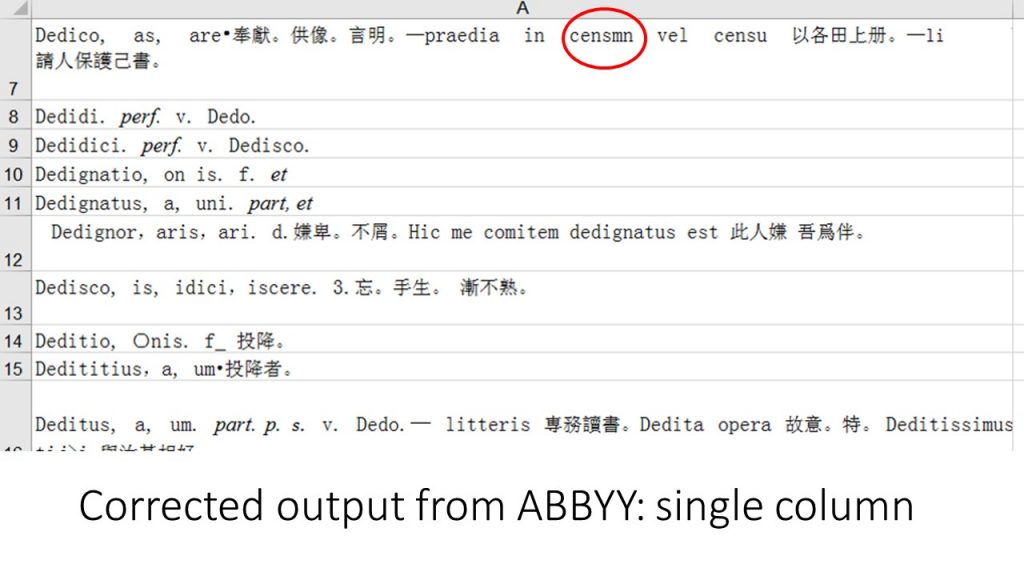
 After digitization by NewGen Knowledge Works it looks like this:
After digitization by NewGen Knowledge Works it looks like this:
<il><B>scirp-us:</B></il>
<il> -o (ab): An 941</il>
<il><B>Scirt-us:</B></il>
<il> -e: Hc 78</il>
<il><B>sciscit-or:</B></il>
<il> -ari: E 548</il>
<il><B>scite</B> (3): Ht 729 764 785</il>
<il><B>scit-us</B> (pa; 5):</il>
<il> -a (ns): P 110</il>
<il> -um (ac): E 254</il>
<il> -um (n): Ht 210; P 821</il>
<il> -us: An 486 (in tmesis w per)</il>
<il><B>scopul-us:</B></il>
<il> -um: P 689(4)</il>
<il><B>scort-or</B> (2):</il>
<il> -ari: Ad 102; Ht 206</il>
<il> -atur: Ad 117(F)</il>
<il><B>scortum</B> (ac; 2): Ad 965; E 424</il>
<il><B>screatus</B> (ac): Ht 373</il>
<il><B>scrib-o</B> (19):</il>
<il> -am (ind): P 127</il>
<il> -at: P 3</il>
<il> -endo (g ab): E 7</il>
<il> -endum (g): Ad 25; An 1</il>
<il> -ere: Ad 16; E 36; Hc 56</il>
<il> -eret: Hc 27</il>
<il> -ito (3): P 668</il>
<il> -undis (ab): An 5</il>
<il> -unt: Ht 43</il>
<il> scripserit (subj): Hc 7a(DT); Ht 7</il>
<il> scripsit: E 10; Hc 6; Ht 15; P 6</il>
<il> scripta (sunt): An 283</il>
<il> scriptam (sc esse): P 329</il>
Skalak’s concordance processor will convert this into a spreadsheet with each piece of information in its proper category: lemma or headword (column 1), lemma homonym distinguisher, if any (column 2), citation for specific word forms (column 3), the word forms (column 4), word form homonym distinguishers or other information about a single word form (column 5), and textual variant information (column 6). The trick to the pre-processing analysis is to find the machine-readable characteristics of each kind of information, so the processor can be adjusted to the specific conventions used by the index. Examination revealed the following:
- Lemmas [column 1] are introduced by <il><B> and terminated by a colon. The closing </B> tag may follow or precede the colon, but it will always be there. Only lemmas are enclosed with <B>…</B> tags. The colon is followed by </il>, </B></il>, or by one or more citations and </il>.Examples:
- <il><B>abrad-o:</B></il>
- <il><B>a</B> (prep; 87):</il>
- <il><B>accurate:</B> An 494</il>
- <il><B>abhinc</B> (3): An 69; Hc 822; P 1017</il>
- Lemma distinguishers [column 2] sometimes precede (but never follow) the colon, and are in parentheses. This either indicates the number of times that the lemma occurs, or homonym distinguishers, or textual information, or some combination of the three, set apart with semicola. This info needs to go in column 2 next to every word form under that lemma.
- <il><B>ac-er</B> (2):</il>
- <il><B>act-us</B> (subs):</il>
- <il><B>ad-eo</B> (verb; 26):</il>
- <il><B>dehinc</B> (de(h)inc=KL; 8): Ad 22; An 22 79(dein=4) 190 562 (dein=4); E 14 296 872</il>
- Word forms [column 4] sometimes directly follow the lemma after the colon and before the closing </il> tag (as just above). But in most cases they are listed on a new line, preceded by <il> and a tab, and followed by a colon.
- <il><B>depecto:</B></il>
- <il> depexum (ac): Ht 951</il>
- <il><B>deper-eo:</B></il>
- <il> -it: Ht 525</il>
- <il><B>delir-o</B> (5):</il>
- <il> -ans (n): Ad 761</il>
- <il> -as: Ad 936; An 752; P 801</il>
- <il> -at: P 997</il>
- Word form modifiers [column 5] sometimes follow the word form in parentheses, before the colon. This information can be syntactical (most common) or textual, can indicate matter to be assumed, differentiate homonymns, or indicate frequency. Put this in column 4 next to every instance of the word form.
- <il> aspexerit (subj): Ht 773</il>
- <il> -andus (est): Ad 709</il>
- <il>ante (adv; 6): An 239 556; E 733; Hc 146 581; P 4(antehac=DU)</il>
- <il> -quid (-quit=U sometimes; ac): Ad 38 150 401 518 856 857 948 980; An 250 259 265(om=DU) 615 622 640; E 210 308 661 999 1001; Hc 333; Ht 69 339 533 670 763 1003; P 42 190 770 874</il>
- Citations for instances of a word form [column 3] in each of the six plays follow the colon. Semicola separate instances for each play. Multiple citations from a single play are separated by a space only. </il> closes off the word form.
- <il><B>de-us</B> (121):</il>
- <il> -o (ab): P 74</il>
- <il> -orum: An 959(sp=U); Ht 693</il>
- <il> -os: Ad 275 298 491 693 699 704; An 487 522 538 664 694 834; Hc 476 772 772; Ht 879 1038; P 311 764</il>
- The string “ae” followed directly by numerals (no spaces) should be treated as part of the numeral. This indicates the line numbers in the alternate ending of the Andria. Some line numbers will have a letter suffix, like 7a, 7b
- <il> -averis (ind): An ae16</il>
- Citation modifiers in parentheses [column 6].These are all textual variants. Depending on what it says, sometimes the parenthetical material only will be deleted, sometimes the citation will be deleted as well. This can be done after the creation of the spreadsheet. If the citation-distinguishing parenthesis in column 6 contains ‘=’, delete just the parenthesis. If it does not contain ‘=’, delete the entire citation and the parenthesis. Column 6 will then be gone.
- <il><B>ergo</B> (38): Ad 172(ego me=F) 324 325(FT) 326 572 609 854 959; An 195 565 711 850; E 162 317 401 459 796 1062; Hc 63 610 611 715 787(4); Ht 398 550 821 985 993 (ego=FU) 1046; P 62 202 539 562 685 718 755 882 948 984 995</il>
- <il><B>et</B> (538): Ad 2 19 30 34 35(om=4) 43 57 64 65 68 78 107 121 121(F) 122 129 138 144 207 230 251 263 272 279(F) 285 285 305 316 319 340 352 380 389 (U) 391 423 429 446 495 511 521 523 558 566 580 584(ei=F) 591 596 600(esse=FTU) 602 603 609 609 648 675 680 683 692 (4)
- Lemmas sometimes have hyphens to indicate that subsequent inflected forms may be abbreviated. They may or may not actually be abbreviated. Word forms can be reconstructed by combining.
- <il><B>adfer-o</B> (25):</il>
- <il> -: Ht 223</il>
- <il> -am (ind): Ht 701</il>
- <il> -ant: Ad 300</il>
- <il><B>admitt-o</B> (13):</il>
- <il> admiserit (subj): P 270</il>
- <il> admisero: E 853</il>
I made some alterations to the concordance to make it easier to process:
- To avoid confusion, citations that are themselves in parentheses had to be removed from parentheses. Otherwise they will be treated as supplementary info for the previous citation.
- Alphabetic headings had to be removed, since they looked superficially like lemmas.
- Spurious lines in square brackets were removed.
- All 59 instances of “*” were removed. The asterisk indicates that some minor point applies, e.g. that est is to be inferred with factum, or that ipsa is spelled eapse in F’s edition. This information was not significant enough for our purpose, which was to get each word form sitting next to its proper lemma.
After the spreadsheet is done I’ll check it, then hand it over to Bret Mulligan, who will ingest the parsed text into the Bride, adding Bridge display lemmas and definitions. Custom vocabulary lists can be created from there. The original .txt and the spreadsheet version will also be made available on our Github repository.