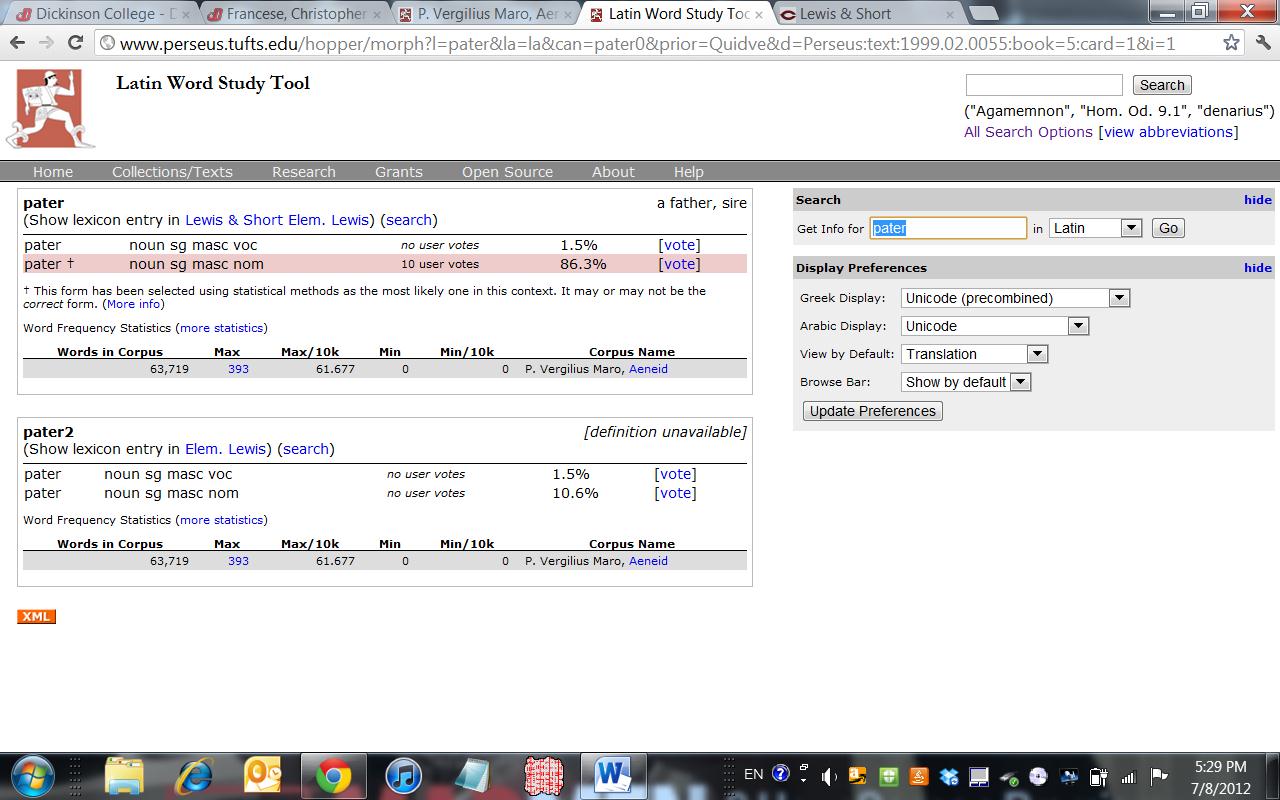
In a recent post I tried to categorize the problems of the Perseus Word Study Tool, as tested on a section of Vergil. More surprising to me than the overall rate of error (about one in three words was misidentified in some way) was the fact that many of the errors were not subject to correction by means of Perseus’ “voting” system; and that even when voting was in operation, it often did not correct the error. Sometimes the correct choice was not an available option; other times, unanimous correct votes were ignored, and unanimous incorrect votes were accepted. At Aen. 5.17, to add another example to those mentioned the earlier post, the vocative magnanime was incorrectly called an adverb on the basis of six incorrect user votes.
The inadequacy of the LWST will not have been news to anyone who has used it. The question is, is the level of error pedagogically significant? Is the LWST good enough for the purposes of a typical Latin student? In other words, should the average Latinist care? It is not good enough, and the level of error and the specific types of errors in this flagship classical DH project are pedagogically significant and worthy of attention, I believe, for several reasons.
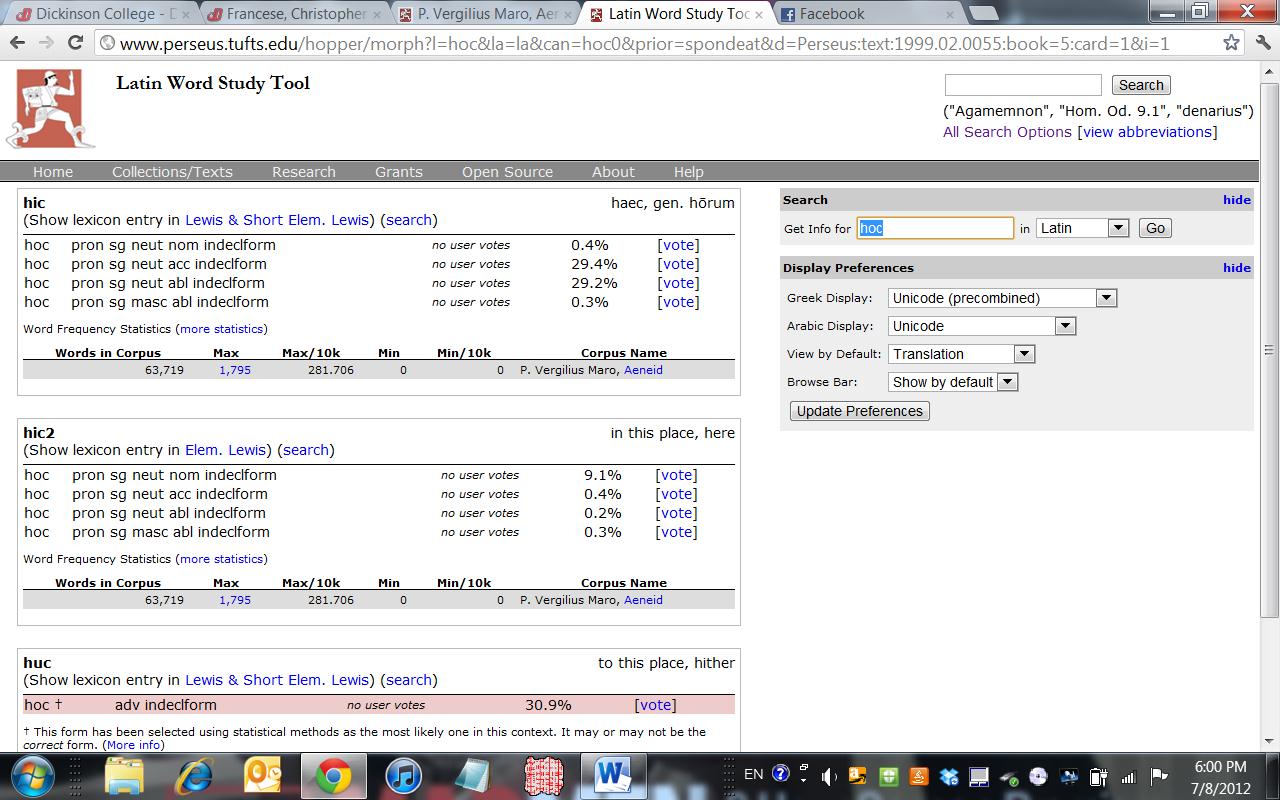
1. Words that give students the most trouble–relative pronouns, demonstratives, quam, ut, modo, Q-words in general–are exactly those least likely to be handled well by the LWST. The earlier post has some examples from my small sample, but I’ll add here that in Aen. 5.30 (magis . . . ) quam, when it comes to that quam, the LWST offered no fewer than seven possible quams to choose from (all numbered quam 1-7), none of which has the correct definition in the context (“than”).
2. The LWST is of course helpless when it comes to unusual or idiomatic expressions, of which there is a good example in my sample at 5.6, were notum must be translated “the knowledge that.”
3. The tool naturally can analyze only what is there. It cannot tell when something is left out or assumed.
4. A major structural problem is represented by bad short definitions of the type (to choose again from examples offered by my sample) iubet = “imposed,” iam = “are you going so soon,” frustra = “in deception, in error,” or more subtly, the fact that the common meaning of tendere, “direct one’s course,” does not appear in the short def. for that word.This is important because, even though one can click on and read the full Lewis & Short dictoinary definition, intermediate students are very unlikely to click through and sift through long entries in search of the correct definition.
5. Moreover, the LWST obscures the relationships between words, which is key to learning to read Latin. This is why seemingly minor accidence mistakes are meaningful. Misled on a part of speech, or the gender of an adjective or the case of a noun, the student will likely not see the syntactical connection between words, and thus the tool reinforces the urge to produce the dreaded “word salad” translations.
6. More broadly, with its cryptic statistical data and jumbled pseudo-information, the LWST reinforces the the impression that many students have: that Latin isn’t really supposed to make sense anyway, that it’s all some kind of fiendish crossword puzzle.
Gregory Crane in an important article and apologia for Perseus, has said that the goal of the Perseus Project is to provide “machine-actionable knowledge.”
Reference materials, in particular, are structured to support automatic systems (e.g., the morphological analyzer learns Greek and Latin morphology from a machine actionable grammar) and to be decomposed into small chunks and then recombined to provide dynamic commentaries. If you retrieve a book in a language that you cannot read or on a topic that you cannot understand, the system can find translations where these already exist, machine translation and translation support systems, reference works, and general background information suited to the general background and immediate purposes of the reader. In knowledge bases, the boundaries between books begin to dissolve.
But clearly machines are spectacularly bad at understanding Latin at the moment. Crane thinks in terms of many decades, and is waiting for massive improvements in artificial intelligence, or teams of graduate students to encode correct grammatical analysis in texts. But such a prospect seems increasingly far off, and given the size of the Perseus Digital Library (10.5 million words at the moment), it seem unlikely that the millions of errors can be corrected any time soon, if ever. Indeed, would it be worth huge the investment of time and money? In the meantime, we need to create a collaborative tool for generating reasonably correct and reliable vocabulary lists for Latin (and Greek) authors that will be helpful for students and teachers around the world. Why we should do this, and what kind of tool I have in mind, will be the subjects of future posts.
–Chris Francese