The Perseus Latin Word Study Tool (LWST) is intended to provide dictionary definitions and grammatical analysis of all words in the Latin texts available in the Perseus Digital Library, currently 10.5 million words.
A check of the definitions and grammatical analysis of an arbitrarily chosen chunk of Vergil’s Aeneid (5.1-34, 223 words), found that it was incorrect in 79 instances, or 35.4% of the time (and correct 64.6% of the time). The most common type of error (21 instances, 26.6% of all errors, 9.4% of all words) was a mistake of accidence, for example duri (5.5) was taken as genitive singular instead of nominative plural. In 17 cases (21.5% of errors, 7.6% of all words) words were assigned to the wrong lemma, as when quoque (“and whither”) was derived from quoque (“also, too”), or venti (“winds,” 5.20) was assigned to the verb venio, “come,” as if it were the perfect participle. This particular mistake occurred three times in this passage, and the correct lemma was not listed as a possible option. In 14 instances (17.7% of errors, 6.3% of all words) the dictionary definitions provided were wildly wrong. This was true of some very common words. iam was glossed as “are you going so soon,” nec as “and not yet,” ab as “all the way from.” Elissae (5.3) was glossed as “Hannibal.” In every case this type of error was seen to come from the pulling, seemingly at random, of a word or phrase from the dictionary of Lewis & Short on which the LWRT is based. In 11 instances (13.9% of errors, 4.9% of all words), the relevant definition in the context at hand was not provided (though it could be found by clicking to and reading through the full Lewis & Short dictionary entry). For example, cerno was glossed as “separate, part, sift,” but not “perceive,” or infelicis (5.3) glossed as “unfruitful, not fertile barren,” rather than “unfortunate.” More seriously, all relative pronouns were glossed as interrogatives (“who? which? what? what kind of a?”), and described simply as “pron.” The word “relative” did not appear on the page. In 8 instances (10% of errors, 3.6% of all words) a word was assigned to the incorrect part of speech, as when medium (5.1) was called a noun rather than an adjective, or locutus (5.14) assigned to the rare 4th decl. noun “a speaking” rather than to loquor. In 4 cases (5% of errors, 1.8% of all words), there was no definition available. And in all cases deponent verbs were incorrectly labeled passive (4 instances in this particular section, or 5% of errors, 1.8% of all words).
Now, the makers of Perseus are perfectly aware of the flaws in LWST, and attempt to use the power of social media of help remedy the situation. Subjoined to the analysis of every ambiguous word, after an explanation of the methodology used, one finds a plea to help by voting.
The possible parses for this word have been evaluated by an experimental system that attempts to determine which parse is correct in this context. The system is composed of a number of “evaluators”–each of which uses different criteria to score the possibilities–whose votes are weighted to determine the best answer. The percentages in the table above show each evaluator’s score for each form, which are then combined to determine each form’s overall score.
This selection used the following evaluators:
• User-voting evaluator: Scores parses based on the number of votes each one has received from users. Weighted more heavily as more users vote for a given word in a text.
• Prior-form frequency evaluator: Evaluates forms based on the preceding word in the text; finds the most likely parse among this word’s possible morphological features and the preceding word’s possible features based on the frequency of each possible pair.
• Word-frequency evaluator: Scores parses based on how often the dictionary word appears in the Perseus corpus. Only used when a given form could be from more than one possible word.
• Tagger evaluator: Evaluator based on pre-computed automatic morphological tagging
• Form frequency evaluator: Scores parses based on how often their morphological features (first-person, indicative, plural, and so on) occur among all the words in the Perseus corpus.
User votes are weighted more heavily than the other methods, which are all treated equally.
Don’t agree with the results? Cast your vote for the correct form by clicking on the [vote] link to the right of the form above!
But here too, some problems arose in my sample. First of all, only a handful of doubtful words had any votes. Second, many of the error types identified above do not admit of voting. And third, those that did have votes did not always benefit from having them. Here is the entry on the word rates in ut pelagus tenuere rates (5.8), showing a preference for the (incorrect) accusative, despite nine user votes for the (correct) nominative.

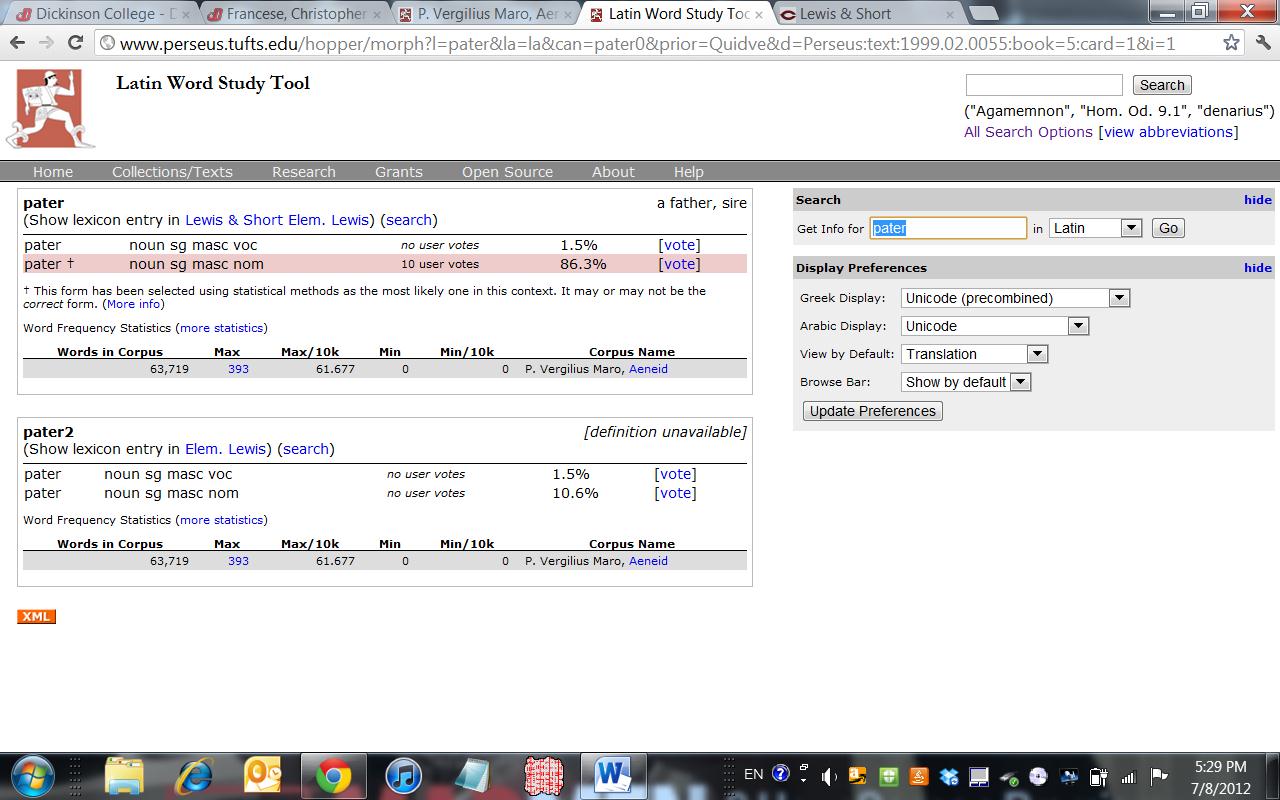
On the word pater in Quidve, pater Neptune, paras? (5.14), ten incorrect user votes for the nominative win out over the (obviously correct) vocative.
More common, however, is the lack of any user votes at all, as in this very confusing jumble of information on the word hoc (5.18). 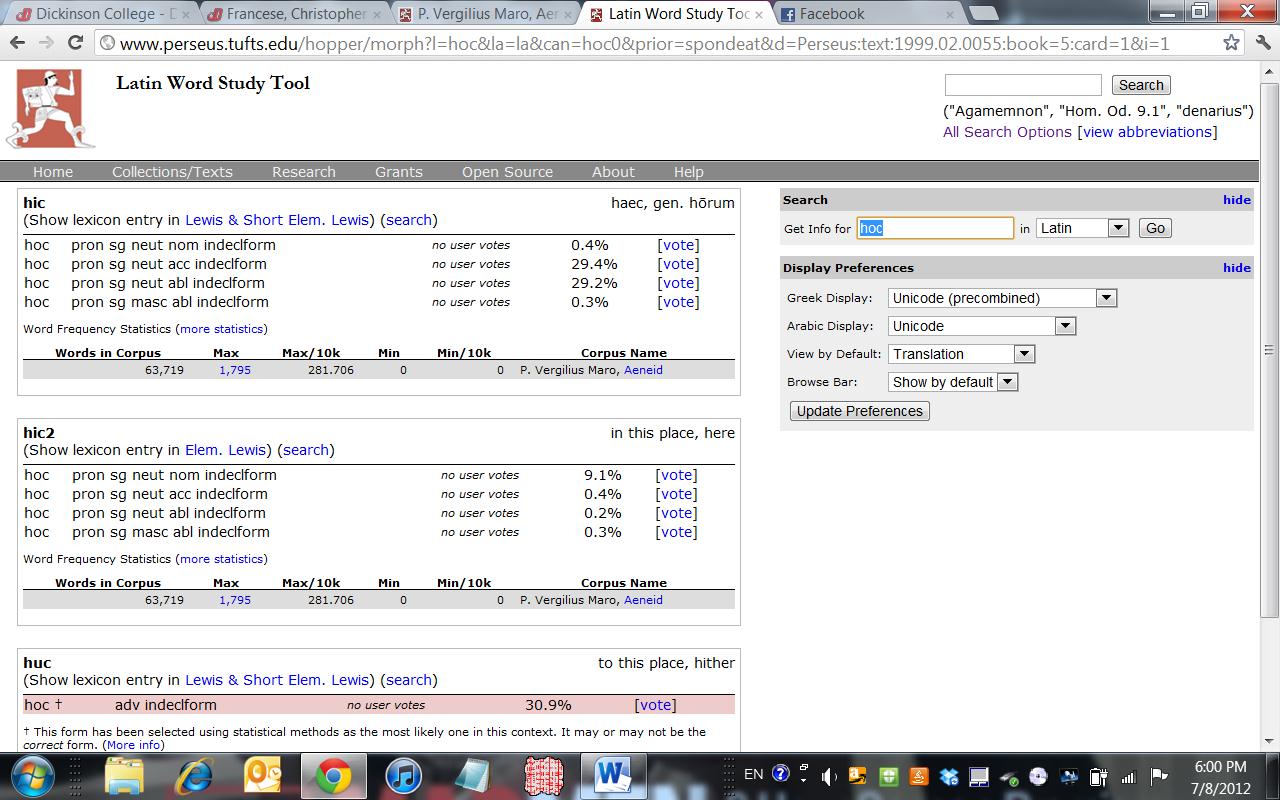 Note that the correct lemmatization (> hic) has a nonsensical definition; that the morphological analysis states it can only be a pronoun (“pron.”) whereas here, as often, it is a demonstrative adjective; and finally that the LWST incorrectly concludes that the form derives from the lemma huc.
Note that the correct lemmatization (> hic) has a nonsensical definition; that the morphological analysis states it can only be a pronoun (“pron.”) whereas here, as often, it is a demonstrative adjective; and finally that the LWST incorrectly concludes that the form derives from the lemma huc.
Another odd and thankfully rare genre of error occurs in the case of deinde (5.14), which is correctly analyzed, but put beside a fictional alternative, the present imperative of a verb *deindo.
I would like to know if the same level of error and types of errors occur when LWST is unleashed on a prose text. Perhaps there the idea of a “prior-form frequency evaluator” would make more sense.
It is not my intent to denigrate the huge achievements of Perseus in our field. It is certainly better to have the LWST than not to have it. My purpose here is just to investigate the nature and extent of its errors. If this sample is at all representative, something along the lines of 3.5 million errors exist in the current database. I would also like to ask, is it realistic to think that qualified people can be found to correct the mistakes of the LWST? What is the incentive for professional Latinists to do so?
I also have a proposal for a different kind of tool, which I will save for another post, since this one is already too long. Your thoughts?
–Chris Francese