[The following slides and presentation notes are from Cliff Wulfman’s talk, “Thinking Big,” which took place Thursday, April 2, 2015 in Stafford Auditorium on the campus of Dickinson College. The Digital Humanities Advisory Committee thanks Dr. Wulfman for his permission to share them–PSB].

I want to thank Chris and Patrick for inviting me to speak with you this afternoon. I’m a close reader by training and inclination, so I can’t start a talk like this without “problematizing” our terms:
“Successful Digital Humanities Project Development”
Indeed, I’m going to use those terms as the framework for exploring these five steps, though not in syntactic order.
1. DIGITAL: Let’s begin with the term digital, and its verbal derivation, digitize.

The term digital is, of course, treacherously polysemous. It has become a metonym for the discrete values modern computers use to represent information, and so to digitize is to represent information by means of discrete values. Digital data is simply information stored as ordered sequences of discrete states. These ordered sequences are often called files or streams, and they come in many varieties, but at the most basic level they are all the same: audio files, image files, text files are all just sequences of bits.
So the digital in digital humanities refers to the binary representation of information as bits. It does not, in other words, connote numerical or mathematical so much as it does symbolic, or semiotic.

It is about representability.
So digital humanities is not equivalent to statistical humanities, although the showiest face of digital humanities is the visualization of maps, graphs, and trees derived from the application of social-science methods to texts and to phenomena of interest to historians of various types, literary and otherwise. The rhetorical impact of these visualizations is undeniable, but at bottom they are simply a way of displaying quantitative information, and computation is not equivalent to quantification. Computation also entails the application of procedural logic and heuristics: using an encoded knowledge base and a reasoning algorithm, for example, to diagnose an illness from a set of symptoms.
Nor is digital humanities equivalent to making web pages.

For scholars in the humanities, in most cases, web sites are akin to publications: they constitute the presentation of research, not the research itself. So in almost all cases, creating a web site does not constitute a digital humanities project.
At the same time, the World Wide Web has evolved, from a collection of lightly encoded text files linked together by the HTTP data-transfer protocol, into a network of data and services. So creating a trove of carefully prepared data in machine-readable format — a digital edition encoded in the schema of the Text Encoding Initiative, for example, or a biographical dictionary encoded using the standards of linked open data — does constitute a digital humanities project.
So the first step to successful digital humanities project development is understanding what it means for something to be digital.
2. PROJECT: Next: Defining a project.

As a researcher, you may already have disciplinary knowledge and traditional practice guiding and constraining your conception and realization of a project. What makes a scholarly or academic project a digital humanities project?
Defining a project isn’t always straightforward in the humanities.

These endeavors are not always product-oriented; even when they are, the product is frequently intangible: an idea; an argument; an analysis; a method; a critique; etc. I’m leaving aside articles and monographs as direct products of research: they are secondary instruments of dissemination
Sometimes there is tangible product, though: editions; transcriptions; databases; instruments for research and analysis.
When thinking in terms of a project, then, it is important to learn to think strategically:
 Think about the outcomes you want to want to achieve, and why they are important: what will the consequences of this work be?
Think about the outcomes you want to want to achieve, and why they are important: what will the consequences of this work be?
Think about the resources your work will require. Particular materials, in particular forms? Tools for accomplishing specific tasks? Whose time and attention will you be drawing upon, and for how long?
How difficult is your project? What are the risk factors: what sorts of things might go wrong, what sorts of events might interfere with the successful completion of your project? What are your contingency plans? Can your project produce partial successes, or is it all or nothing? (Not a good idea.)
Try to organize your project into phases, each of which has its own success criteria, and each of which builds on the preceding phases.
If it sounds like I’m telling you to learn to think like an engineer, I am.
3. HUMANITIES:

Earlier, I talked about what it means for something to be digital. Chiseling a definition of the term digital is easy; sharpening the meaning of the term humanities is much, much more difficult – so difficult and contentious, in fact, that I’m not going to address it directly at all, other than to suggest it has more to do with subject-matter than method. Instead, just as I have tried to complicate the popular conflation of digital humanities with social science, I want to take this opportunity to distinguish digital humanities from digital librarianship. Once again, these endeavors often overlap significantly, but they are different.
From one perspective, a library is a hoard of physical artifacts whose principal function is to be looked at. Seen from that perspective, digitization is an image-making activity: rendering surfaces on which drawings and inscriptions appear into sequences of bits that a computer can use to produce a reflection of that surface. From another perspective, a library is a gathering of texts whose principal function is to be read. From this perspective digitization is a linguistic activity: rendering words or other symbols into sequences of bits that a computer can use to create linguistic symbols that can be analyzed and compared.
It is the scholar’s privilege to regard the library from the latter perspective; it is the librarian’s burden to view it from the former, and in large measure the job of libraries is conservative digital photo-duplication: not creating a digital library so much as digitizing an existing one.
Thus the work of the digital scholar depends on that of the digital librarian, and in some aspects overlaps considerably with it, but it is not the same work. Likewise the work of the information scientist; the software engineer; the computer scientist (all different sorts of work, often done by different people).
This is part of the reason the digital humanities are so often hyped as being collaborative: quite often, work in DH requires knowledge and expertise from a variety of fields. By bringing in many different perspectives you necessarily get many different priorities, points of view, cutting across different traditional academic disciplines, but focusing on humanities questions.
So, step three in developing a successful digital humanities project is to conceptualize your work in the context of an interdisciplinary framework of humanistic endeavor.

4. SUCCESSFUL: Defining success isn’t always straightforward in the humanities, and in research in general.

I’m going to hazard the following measure of a good DH Project:
“a good DH project uses domain knowledge and intellectual labor to create digital objects that can be curated and shared with others through standard formats and services.”
That last criterion (accessibility) strongly implicates the world wide web, but it needn’t always. And it certainly doesn’t necessitate a whizzy web site.

But defining success is a useful discipline nonetheless. For one thing, it can help you focus your work by articulating specific outcomes you want to achieve.
What specific goals do you expect to meet with this work? A full and compelling argument? An insightful biography? A meticulous accounting of an event, or an object, or an archive? If there are products of your work, what are they? On what basis can you or others evaluate their quality, their success or failure?
Of course, this kind of outcome-orientation isn’t appropriate at all stages of research, but the point at which you can articulate goals and deliverables is the point at which research becomes a project.

Defining successful outcomes also helps to organize time and effort. Most of us know the value of setting intermediate goals and deadlines; organizing these around success criteria can help make them realistic.
Let me give you some examples (this is a highly opinionated list) of “Bad (or Meh) DH Projects”:




Now another, equally opinionated, list of “Good (or Exemplary) DH Projects”:

The Text Creation Partnership to improve the OCR of 18th century typography is a good DH project. Good DH projects are those whose products or outcomes can be used in multiple ways by others.
EXEMPLARY PROJECTS
The Valley of the Shadow is one of the first digital humanities projects.

Begun in 1993 by Ed Ayers and Will Thomas, at Uva, it is an electronic archive of two communities in the American Civil War–Augusta County, Virginia, and Franklin County, Pennyslvania. The Valley Web site includes encoded, searchable newspapers, population census data, agricultural census data, manufacturing census data, slave-owner census data, and tax records. The Valley Web site also contains letters and diaries, images, maps, church records, and military rosters.
What makes it particularly important, to my mind, is that it was designed not as a showcase but as a working research tool.
Ayers and Thomas published a web-based hypertext article that explicitly uses hypertext and full-text encoded archival material to make an argument.
The Shelley-Godwin Archive is another exemplary archival project.

It features transcriptions of manuscripts that are deeply encoded to allow users to study the composition history of the materials.
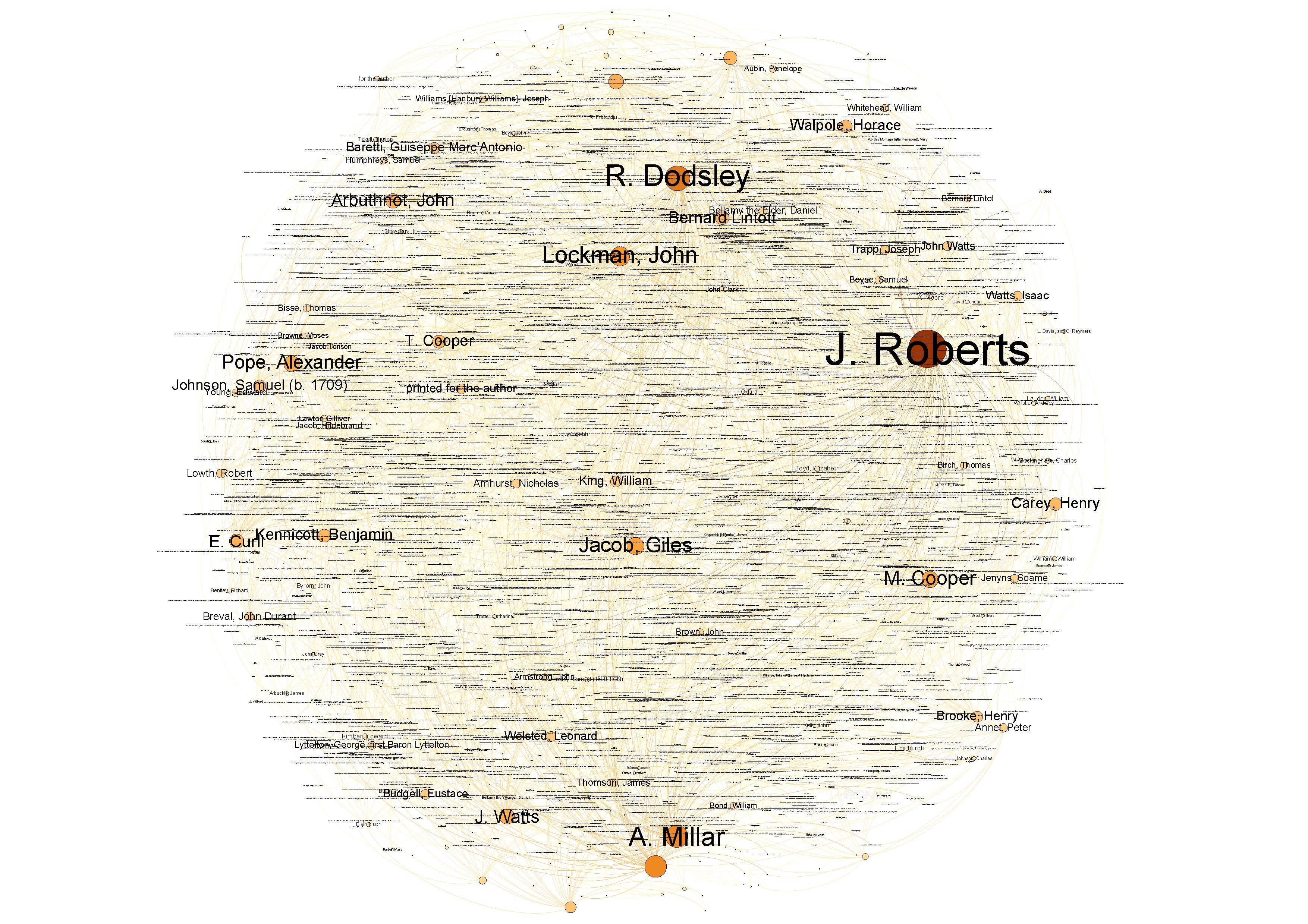
Mapping the Republic of Letters is another.

Based at Stanford, this project gathers meta data about the networks of correspondence among the luminaries of the Age of Enlightenment and uses it to produce wonderful visualizations of them.
5. DEVELOPMENT: So how do you go about doing this? How do you develop a DH project?

Talk with people.
We’ve already talked about the almost inherently collaborative nature of the digital humanities. There simply is not (not yet, anyway) a strong, documented track record of digital humanities methods and approaches; they are in any case highly interdisciplinary and under rapid evolution.
The proliferation of DH centers at universities testifies to the anxiety on the part of researchers to acquire new competencies as part of their academic work. So seek out others in your field who have already had some experience, and ask them how they did it; seek out colleagues in other fields to talk with you about methodologies and approaches.
Climb the steep hill.

This is really important. Ask yourself if you are willing to take the time to learn something new, different, and possibly outside your comfort zone.
Be prepared to acquire a more than superficial understanding of computational practices and methods. Not that you have to become a master programmer; but you should understand the fundamentals of programming and computer science: data structures and algorithms; inputs and outputs.
Just as you would not undertake a professional study of Homer without learning Greek, learn the the language of computer engineering: how could I represent the objects of my study in machine-readable forms? Can I develop models of things and events? How might I manipulate those representations? Could I describe procedures, techniques, tricks for analyzing them, generating them, enhancing them, expressing them in different forms?
Deploy project-oriented thinking.

In developing your project, employ the project-oriented strategic thinking we discussed earlier: Try to lay out your project as a series of incremental steps and accomplishments.
Be flexible.
Unless your project is very straightforward and extremely well defined, it is likely to change in response to external events (funding, personnel) and internal evolution (discoveries made in the course of the project).
But, don’t just go chasing rabbits down the rabbit-hole. It’s very tempting to let the scope of your project expand over time as you learn about new things, see someone’s nifty tool, and so on.
Scope creep founders projects.
At the same time, though, don’t hobble your imagination or your ambition based on what you can see from here, today.
Don’t be afraid to think big.

Let me share with you a little thought experiment. A few months ago I was asked to speak on a conference panel entitled “Modernism and Big Data.”
The so-called “digital humanities” are at this early stage of engagement as much a series of considered poses, or deliberative positions, as anything else. So to hold a panel on “Modernism and Big Data” was to propose a consideration of “Humanism as Big Science,” to position ourselves, to imagine ourselves, as big scientists asking big questions, knowing all the while that we were “playing pretend”.
In what follows, I am going to pretend that the collective textual remnants of the late 19th and early 20th centuries have all been processed into a machine-readable textual corpus. We don’t have it now, but it is not so far-fetched to imagine that we will be able to capture a significant portion of the written record, at least that portion already under institutional control in libraries and archives. It wasn’t all that long ago that the Google Books project seemed absolutely preposterous.
And besides, we’re just playing.

Big Science asks big questions, such as “what is the nature of matter?” The enormity of the question and the value of obtaining an answer (both practical value and intellectual value) drive research, collaboration, funding — they provide the energy that turns the wheels of research.
Perhaps, in this big-science fantasy we’re indulging ourselves in for the moment, we can imagine what such a Big Question might be, and speculate on what sort of engine posing it might awaken. In our context I can imagine no bigger question than Raymond Williams’ question, ”When was Modernism?”
This seems a reasonable — and somewhat preposterous — Big Question to start with. But we could just as easily ask something just as grandiose, like “WHAT was Modernism?” — answering which is a precondition to answering the “When?” question, or “WHERE was Modernism?”

These questions share the playful, tantalizing precision of Virginia Woolf’s famous aphorism from “Mr Bennet and Mrs Brown.”
Less often quoted is her qualification. Nevertheless, let’s succumb to temptation and take Woolf’s assertion at face value. How would we go about proving or disproving her hypothesis? Could the immensity of Big Data help us, and if so, how?
So, in Woolf’s spirit, and since one must be arbitrary, let us call our Big Science endeavor…

We’re talking Big Science here – REALLY BIG – like the Manhattan Project, or the search for the Higgs boson. So let’s keep playing dress-up and imagine an alternative reality where the Institutions of Power actually thought these questions were as important as finding out whether a subatomic particle actually exists or not, or how to blow up the planet. That is, we would have access to REALLY BIG RESOURCES, with really big expectations.
What would it mean for us, institutionally and professionally, to address ourselves collectively to answering such a question? What would happen to the current models of promotion and tenure, department composition, teaching, publication? Who would have to be involved?
We would inevitably want some Theorists.

We want to describe a state change: for some definition of human character, we want to be able to say that before some point (the “December 1910 Moment”), human character was in state H and after that point it was in state H′.
We might then call Modernism a function which, when applied to Human Character H, transforms it to H prime.
As with so much theory, the discussion quickly becomes highly arcane. So I’m going to leave the theorists to do their thing for the moment and turn to the Empiricists.

They’re the ones who get to play with the big toys, the big machines, the big data. Sometimes they get to play pirate, or skunks – more about that in a minute. The linear accelerator model: building a ginormous machine that you can use to produce humungous amounts of data, which you can then search for traces in. The ginormous machine is history, which has left a humungous data trail of artifacts and documents in its wake.
How might the Empiricists use that Big Data to locate the December 1910 Moment?
Well, statistical topic modeling seems pretty tantalizing. If Woolf’s hypothesis is correct, we should expect to find topic models after the December 1910 moment that do not exist before that moment. The simple existence of the moment doesn’t explain what caused the change: that is, it doesn’t explain what the Modernism function is. That’s the problem with History: it isn’t testable. You can’t change the factors in some equation and re-run events to see how the factors affect them.

The Empiricists include scholars like Greg Crane, who ask what do you do with a million books, and Brewster Kahle of the Internet Archive, who asks us to imagine capturing the entire human record in digital form, and Stephen Ramsay, who articulates the Screwmeneutical Imperative to subvert the academic orthodoxies and ideologies of method and form an anarchic version of The December 1910 Project, a “community of practice” that valorizes Roland Barthe’s playful writerly text.
Now, right about now you’re maybe getting a little tired of playing dress-up. But before we pooh-pooh these visionary questions, let’s recall the remarkable thing Google did with its Google Books project. Sure: it isn’t perfect, and it leaves lots of things out, and it’s texts are really, really dirty.
But this is how *big* works. It isn’t small acts of perfection: perfectly crafted editions, for example. Big works through iterative refinement, each iteration changing the state of things in such a way as to open opportunities for further refinement. Unattended OCR, the holy grail: a machine that can read printed text as well as a trained human being. We don’t have it yet, so today the results of unattended OCR are dirty.
But OCR algorithms continue to improve (need citations). In fact, the principal value of generation X digitization projects like the Google Books project is the /page capture/. If those pages were photographed well, the OCR can always be re-run, and over time the cost of processing and re-processing will decline.
So, on the one hand, we must develop research methods that tolerate noise, while at the same time anticipating improvements in the accuracy of text recognition.

The larger message I’m trying to convey is this one. The most valuable part of the December 1910 Project is the social and institutional infrastructure that supports, promotes, protects, and preserves human effort.. Put your emphasis on the stuff that machines need but can’t do. The most expensive, most valuable part of digital humanities work is the work done by trained human beings. That’s the work that can’t be re-processed cheaply, no matter how little you pay graduate students. Don’t treat it lightly! Don’t stick it in a Word document and forget about it. Spend some time thinking about the best ways to capture that intellectual work so that it can be re-used in today’s scholarly world: that may not be a verbal argument published in a scholarly monograph, but a data set – a formal marshalling of evidence – represented in a way that can be taken up by reasoning machines as well as reasoning people.
Don’t become slaves to the machine: hack the machine, or partner with people who can. Make the machine work for you by giving it information it can use.
Give it highly crafted, machine-actionable metadata: not just the usual library metadata – names, titles, dates of publication and so on.

We will need granular structured analyses of complex pages, like those in newspapers and magazines. Not slabs of undifferentiated text, but pages that have been decomposed into their structural regions, mult-page articles that have been joined together into discrete wholes. Much of this work can now be automated, but it still needs human assistance.
Give the machine descriptions of nuanced relations and assertions that it can read.

Statements in first-order predicate logic are a start. Here is a portion of a graph describing the publication of Bayard Boysen’s “Lake” in the first issue of Broom, a description that captures the complex relationships among abstract entities (“the magazine Broom”, “a poem called ‘Lake’”) and concrete realities – a copy of the first issue of Broom, housed in Firestone Library, and a set of electronic files that embody various representations of it. These sorts of assertions – encoded in some sort of standard schema, like RDF – are the raw material of the knowledge base the so-called “semantic web” promises to become. There are lots of problems with the semantic web, just as there are problems with Google Books, but it is for now by far the best place to start putting our scholarly effort.

I want to conclude with a nod to three pioneers of computer science, Vannevar Bush, Douglas Englebart, and J. R. Licklider. At the dawn of the computer age, these men, all three engineers and administrators, each had a vision of the computer that was profoundly humanistic. Bush’s Memex, often cited as the precursor to the world wide web, was a machine that enabled people to link and track the vastness of human knowledge more efficiently.
Doug Englebart, inventor of the mouse and a variety of other ground-breaking technologies, saw in computers the possibility of augmenting the human intellect.
R. Licklider, director of the Defense department’s Advanced Research Projects Agency, from which the Internet sprang, envisioned a “human computer symbiosis” in which humans and machines partner to extend the reach of human thinking and decision-making.
For each of them, the computer was not an enormous calculating machine, but an empowering system that people could engage to increase the store of human knowledge. If you can develop projects that participate in, extend, and augment this vision, they will indeed be successful digital humanities projects.
Which brings us to skunks.

I read with great pleasure and sympathy Bethany Nowviskie’s blog post entitled ‘a skunk in the library’. Nowviskie traces the term to Lockheed Martin in the 1940s, where it was used to describe a “rogue team” of engineers who functioned outside the usual corporate culture in order to accomplish special things, and she applies it to to the Scholar’s Lab at UVa, which she directs.
Nowviskie mentions parenthetically that the engineers took the term “skunkworks” from Al Capp’s L’il Abner, but she doesn’t pursue the allusion, staying with the meaning that has evolved from the Lockheed Martin appropriation: a group of elite creatives who get special license to do wonderful, innovative things. Following this etymology, those creative people are the skunks. And who wouldn’t want to be a skunk? These skunks are like the kids in the Gifted and Talented program: they may be misfits, some of them, but they’re precious and special, and they smell bad only to Department Chairs, who don’t savor liberty and innovation.
The thing is, that’s not how things were in the hillbilly hamlet of Dogpatch, and I want to conclude with that. (I also want to claim the right to use the term “hillbilly”, as I was born and bred in West Virginia and am proud to be called one.)
In the world of Li’l Abner, the “Skonk Works” was a toxic chemical factory on the outskirts of Dogpatch, where the lone operator, “Big Barnsmell,” crafted a mysterious concoction called ‘skonk oil’ by brewing dead skunks and old shoes in a still. Dozens of Dogpatch residents died every year of the toxic fumes.
According to Ben Rich, the second director of the Lockheed Martin skunk works, the group got its name because the original facility was located next to a toxic-smelling plastics factory and one of the engineers likened their own secretive operation to factory in the Al Capp cartoon.

So there are several things to think about here. First, the skunks aren’t in charge. They aren’t the workers in the “Skonk Works”; they are the raw material. Second, the work of the skunk works isn’t benign “creative innovation”; it is industrial pollution. Nowviskie acknowledges the unease occasioned by use of the term “skunkworks”: “there’s a level of honesty and self-awareness involved in not calling them snuggly bunnies.”
There’s a larger story here about papering over the toxic effects of the digital revolution, literally, as in the waste byproducts of microchip manufacture, and figuratively in the effects of automation on an underclass of workers (the denizens of Dogpatch) and the fact that the Lockheed Martin operation designed war planes. These bunnies are not snuggly at all, and they aren’t even amusingly off-beat: they are fodder for a noxious process of commodification.
I’m afraid that to expect academia to work like Lockheed Martin, or like Silicon Valley start-ups, or even like a forward-looking library, is naïve. From what I’ve seen, the skunks are the graduate students, the adjuncts, and the alt-acs who do the work but don’t get the credit; who build the intellectual playgrounds Steve Ramsay describes but aren’t allowed inside. To call them skunks is to give them a roguish tang; in fact, they risk becoming that other legendary Al Capp creature …

The Shmoo, which exists to be a commodity: delicious to eat, and eager to be eaten.
The Digital Humanities, Big Data: these highfalutin terms promise much, and we can fantasize about the opportunities they open up, the roles they may let us play, the discoveries they may enable. But let’s not allow our dress-up fantasies to become wish-fulfillment. Higher Education is in crisis; intellectualism is in decline; graduate education is in a death spiral. Let’s not pretend that DH is going to solve all these problems: even more, let’s not let DH become part of the problem.
Thank you.